










讯飞面经
作者:好圆
链接:https://www.nowcoder.com/discuss/605305?channel=-1&source_id=profile_follow_post_nctrack
来源:牛客网
面经01
1.OSI七层模型介绍
OSI七层模型是国际标准化组织(ISO)制定的一个用于计算机或通讯系统间互联的标准体系
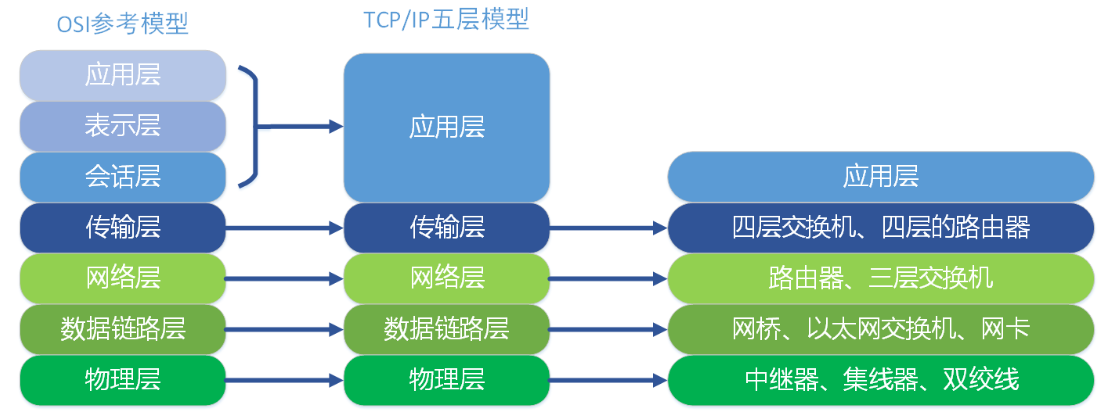
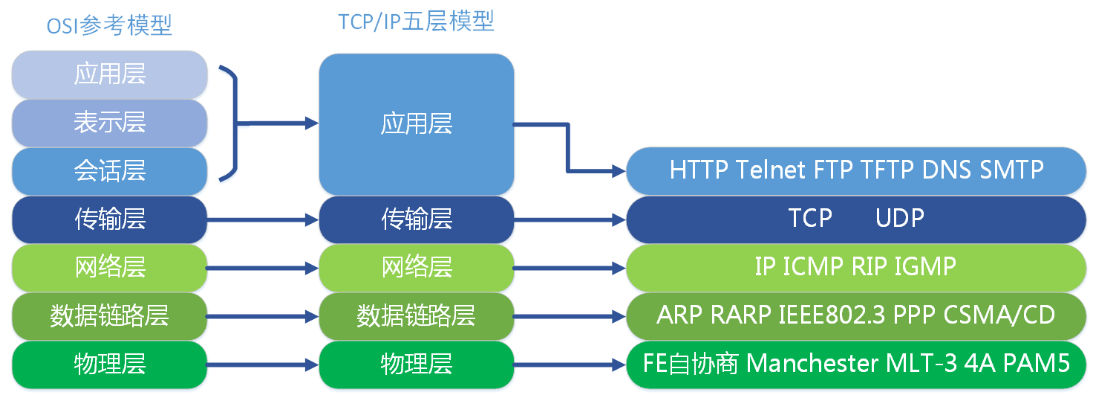
应用层:为计算机用户提供应用接口,也为用户直接提供各种网络服务。
表示层:提供各种用于应用层数据的编码和转换功能,确保一个系统的应用层发送的数据能被另一个系统的应用层识别。
会话层:就是负责建立、管理和终止表示层实体之间的通信会话。
传输层:建立了主机端到端的链接。
网络层:通过IP寻址来建立两个节点之间的连接。
数据链路层 :将比特组合成字节,再将字节组合成帧,使用链路层地址 (以太网使用MAC地址)来访问介质,并进行差错检测。
物理层 : 实际最终信号的传输是通过物理层实现的。
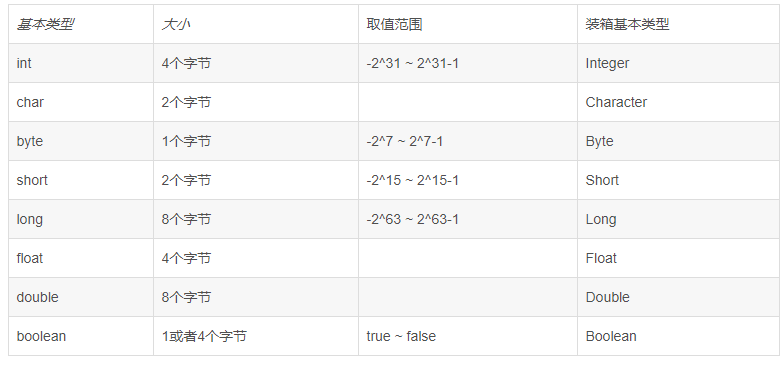
2.Java八种基本数据类型
byte、short、int、long、float、double、boolean、char
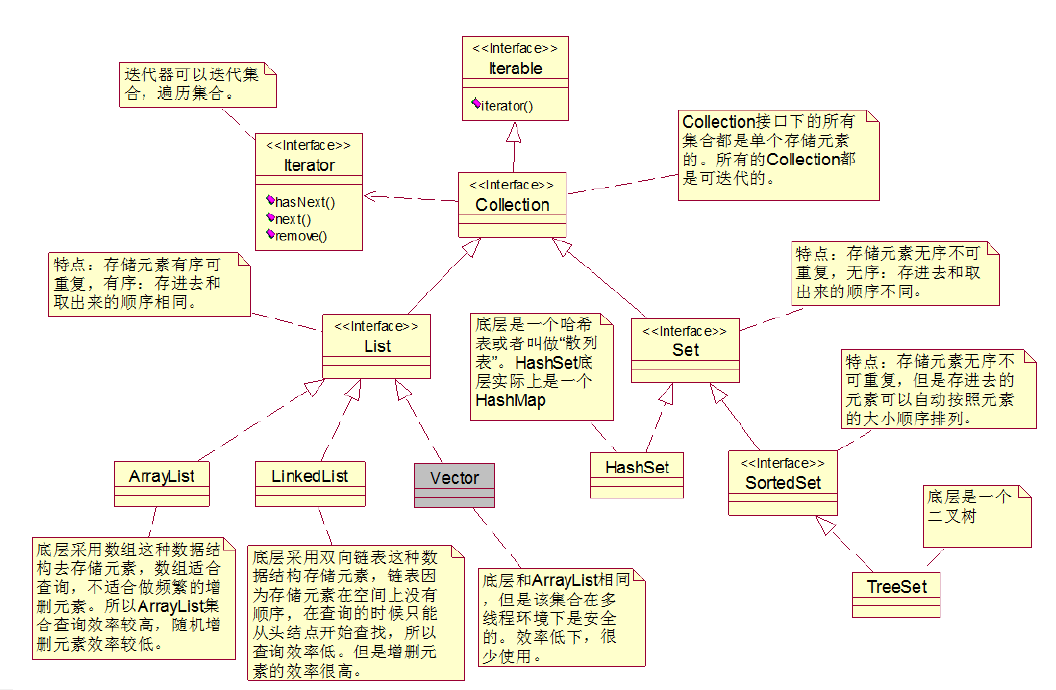
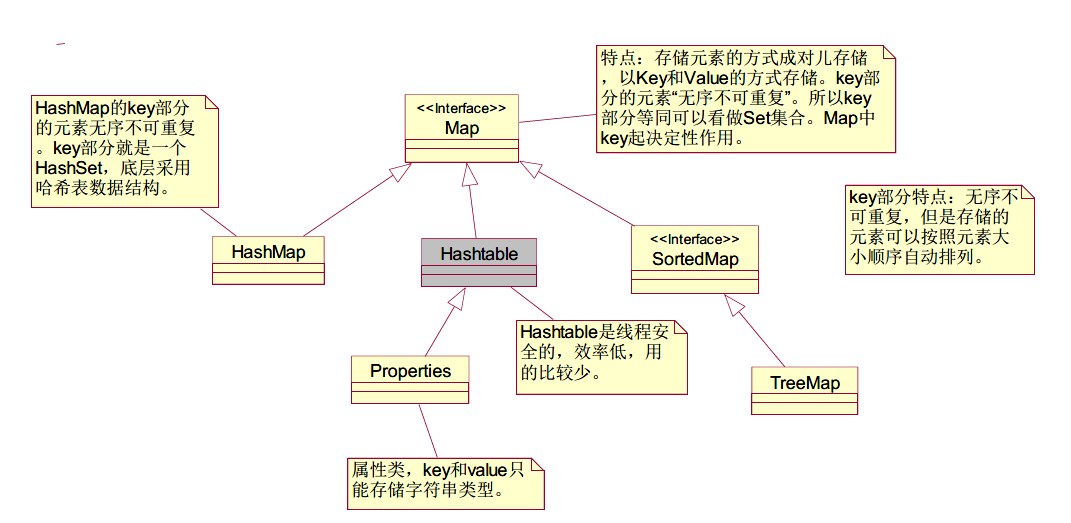
3.Java常用的容器类介绍
Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。
Collection:一个独立元素的序列,这些元素都服从一条或者多条规则。
(list有序可重复,set无序不可重复)
Map:一组成对的“键值对”对象,允许你使用键来查找值。
继承结构图
遍历方法
import java.util.*;
public class Test{
public static void main(String[] args) {
List<String> list=new ArrayList<String>();
list.add("Hello");
list.add("World");
list.add("HAHAHAHA");
//第一种遍历方法使用 For-Each 遍历 List
for (String str : list) { //也可以改写 for(int i=0;i<list.size();i++) 这种形式
System.out.println(str);
}
//第二种遍历,把链表变为数组相关的内容进行遍历
String[] strArray=new String[list.size()];
list.toArray(strArray);
for(int i=0;i<strArray.length;i++) //这里也可以改写为 for(String str:strArray) 这种形式
{
System.out.println(strArray[i]);
}
//第三种遍历 使用迭代器进行相关遍历
Iterator<String> ite=list.iterator();
while(ite.hasNext())//判断下一个元素之后有值
{
System.out.println(ite.next());
}
}
}import java.util.*;
public class Test{
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
//第一种:普遍使用,二次取值
System.out.println("通过Map.keySet遍历key和value:");
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
//第二种
System.out.println("通过Map.entrySet使用iterator遍历key和value:");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第三种:推荐,尤其是容量大时
System.out.println("通过Map.entrySet遍历key和value");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第四种
System.out.println("通过Map.values()遍历所有的value,但不能遍历key");
for (String v : map.values()) {
System.out.println("value= " + v);
}
}
}如何使用比较器
TreeSet和TreeMap的按照排序顺序来存储元素. 然而,这是通过比较器来精确定义按照什么样的排序顺序
使用 Java Comparator‘
4.HashMap结构
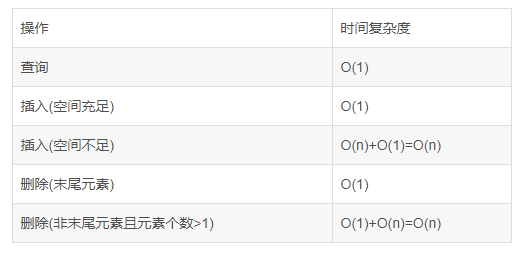
引申到数组和链表操作的时间复杂度
无序数组
有序数组
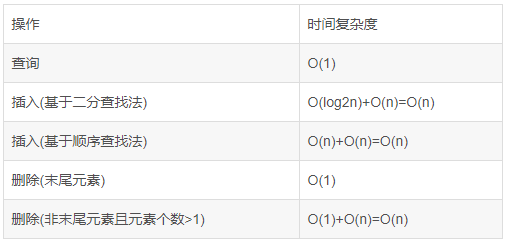
有序链表(失去了链表插入快的特性)

无序链表

如何解决哈希冲突
HashMap根据名称可知,其实现方法与Hash表有密切关系。
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
二叉树:对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
哈希表:相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1)**,接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
哈希表原理
数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式),而在上面我们提到过,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字,通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
location = hash(关键字)
其中,hash函数设计的优劣直接影响整体的性能。
哈希冲突
哈希算法存在一个缺点就是哈希冲突。进行数据存储时,我们通过对关键字进行hash时得到的地址已经存储过数据了,这时就会出现哈希冲突。哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,建立公共溢出区法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式。
hashMap工作原理,put,get,hashcode,equal
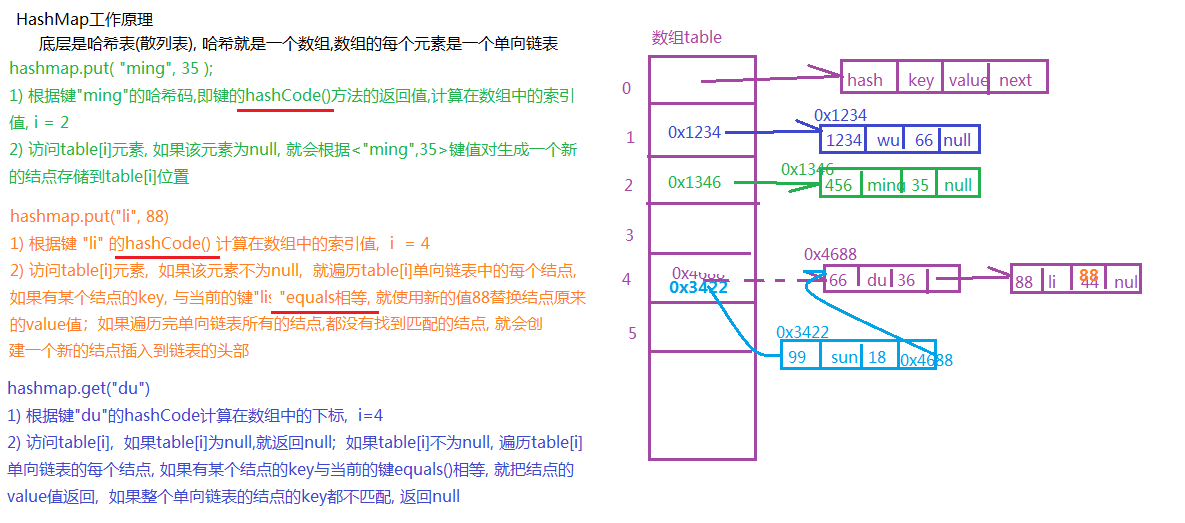
发生哈希冲突并且size大于阈值的时候,需要进行数组扩容,扩容时,需要新建一个长度为之前数组2倍的新的数组,然后将当前的Entry数组中的元素全部传输过去,扩容后的新数组长度为之前的2倍,所以扩容相对来说是个耗资源的操作。
查找算法
什么时候发生死锁
死锁是指这样一种情况:多个线程同时被阻塞,它们中的一个或者全部在等待某个资源被释放或者是都是处于等待而无法被唤醒时,由于线程被无限地阻塞,因此程序不能正常终止。
产生死锁的必要条件:
互斥条件:在一段时间内某资源仅为一进程所占用。
请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
循环等待条件:在发生死锁时,必然存在一个进程–资源的环形链。锁类型
- 可重入锁:在执行对象中所有同步方法不用再次获得锁
- 可中断锁:在等待获取锁过程中可中断
- 公平锁: 按等待获取锁的线程的等待时间进行获取,等待时间长的具有优先获取锁权利
- 读写锁:对资源读取和写入的时候拆分为2部分处理,读的时候可以多线程一起读,写的时候必须同步地写
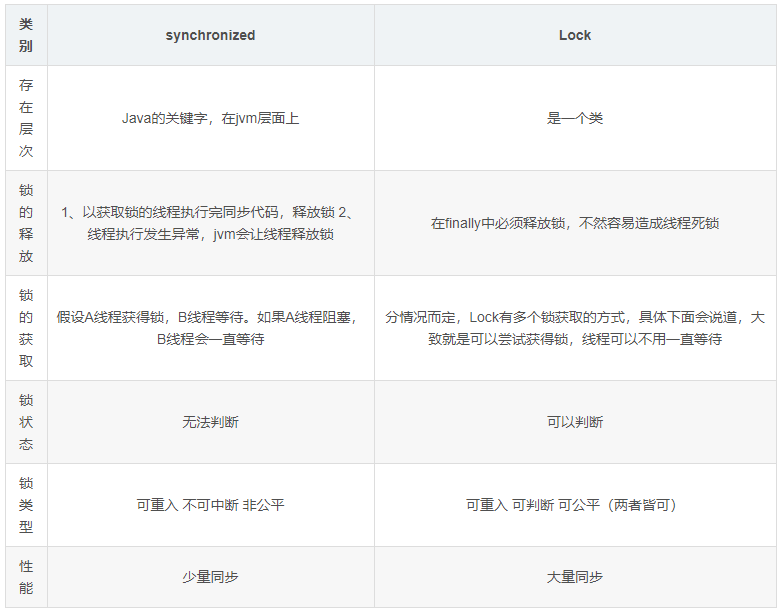
synchronied与Lock区别
5.Java多线程
线程池的种类
- newCachedThreadPool创建一个可缓存线程池程
- newFixedThreadPool 创建一个定长线程池
- newScheduledThreadPool 创建一个周期性执行任务的线程池
- newSingleThreadExecutor 创建一个单线程化的线程池
多线程几种方法
1.继承Thread类,重写run方法
2.实现Runnable接口,重写run方法,实现Runnable接口的实现类的实例对象作为Thread构造函数的target
3.通过Callable和FutureTask创建线程
4.通过线程池创建线程https://blog.csdn.net/java_zyq/article/details/87917734
6.JVM相关
JVM内存分区
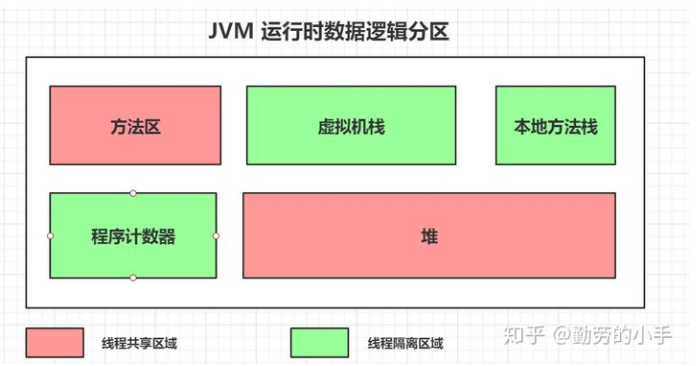
方法区:JVM方法区是用于保存已经被虚拟机加载的类元信息(包括类的版本、字段、方法、接口和父类等信息)、运行时常量信息(static、final定义的常量)、字符串常量信息(String a=”dfc”)。
虚拟机栈:栈这部分区域主要是用于线程运行方法的区域,此区域属于线程私有的空间,每一个线程创建后都会申请一个自己单独的栈空间,每一个方法的调用都会对应着一个栈帧。
本地方法栈:由于java需要与一些底层系统如操作系统或某些硬件交换信息时的情况,这个时候就需要通过调用native本地方法来实现,本地方法栈和虚拟机栈功差不多,区别在于本地方法栈是虚拟机调用native方法时使用的。
程序计数器:程序计数器是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器,程序计数器记录着某个线程当前执行指令的位置,此区域属于线程隔离区。
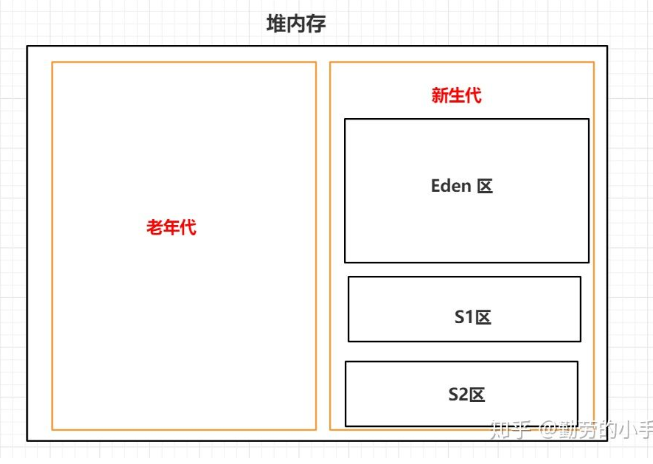
堆:堆内存主要是用来存放创建的对象数据,此区域属于线程共享区对于开发人员来说这块区域是我们关注的比较多,因为很多优化都是针对这块区域来进行的,为了能更清楚的描述堆里的数据和分区信息,所以会结合垃圾回收的一些机制来描述这块内存区域。
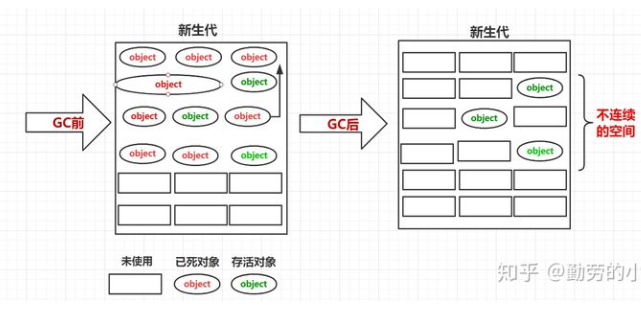
堆->新生代和老年代划分机制:堆内存主要是用来存放我们运行过程中创建的对象数据,根据对象所生存时间长短的特性在逻辑上分为 新生代和老年代。
堆->Eden区和 Survior 划分机制:所以为了减少这种空间碎片,我们就使用了另一种方式,把新生代分为了Eden 区和Survior 区,在进行垃圾回收时,先把存活的对象复制到 Survior 区,然后再对Eden区统一进行清理,这样的话Eden区每次GC过后都是留下的一片连续的空间
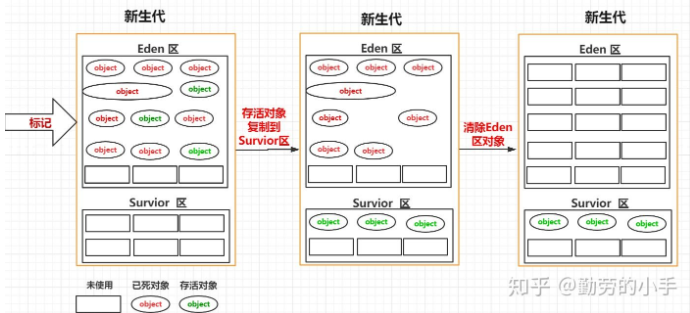
堆->S1 区和S2区划分机制:上面我们把新生代划分为Eden区和Survior区后,空间碎片问题好像改善了很多,因为这样解决了Eden区的空间碎片问题,但是这样的话我们忽略了一个问题,空间碎片问题Survior 区也会存在,因为进行GC时,我们Survior 区也会有垃圾对象,所以每次GC也会对Survior 区进行标记清除,那么这样的话Survior 区也同样会出现不连续的空间。
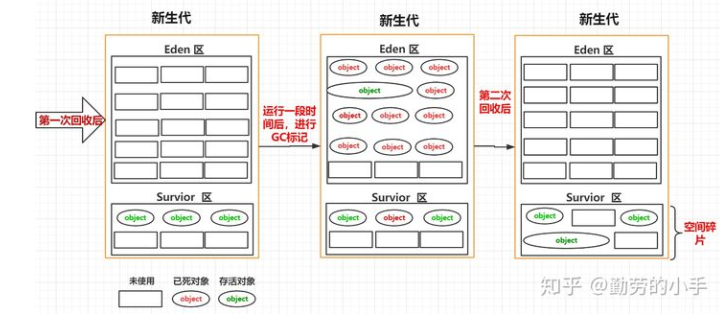
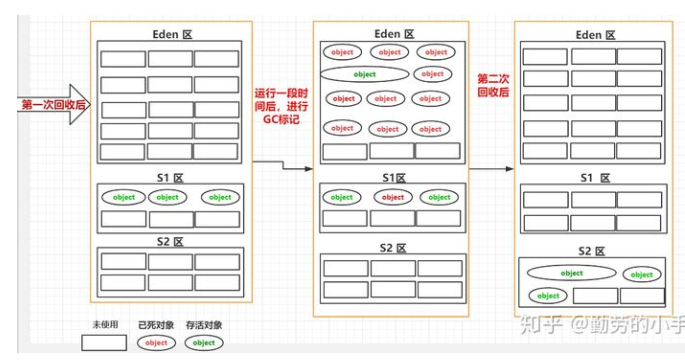
最后经过了一些特定区域职责划分后,堆内存划分为 老年代、新生代,新生代又划分为Eden区、s1区、s2区域。
https://zhuanlan.zhihu.com/p/111370230
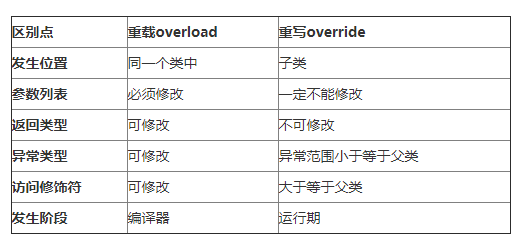
7.重写和重载
https://www.pianshen.com/article/18371043326/
8.面向对象的特点
https://blog.csdn.net/web874418927/article/details/50725994
三大基本特征
封装,继承,多态
封装:也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
继承:可以让某个类型的对象获得另一个类型的对象的属性的方法。
多态:一个类实例的相同方法在不同情形有不同表现形式。
五大基本原则
单一职责原则、开放封闭原则、替换原则、依赖原则、接口分离原则
- 开闭原则:对拓展开放,对修改关闭。
- 里氏代换原则:可以实现子父类互相替换;
- 依赖反转原则:针对接口编程,实现开闭原则的基础;
- 接口隔离原则:降低耦合度,接口单独设计,互相隔离;
- 单一职责原则:一个类的功能要单一,不能包罗万象。
9.普通方法和构造方法区别
1、构造方法的名字必须与定义他的类名完全相同,没有返回类型,甚至连void也没有。
2、类中必定有构造方法,若不写,系统自动添加无参构造方法。接口不允许被实例化,所以接口中没有构造方法。
3、不能被static、final、synchronized、abstract和native修饰。
4、构造方法在初始化对象时自动执行,一般不能显式地直接调用、当同一个类存在多个构造方法时,java编译系统会自动按照初始化时最后面括号的参数个数以及参数类型来自动一一对应。完成构造函数的调用。
5、构造方法分为两种:无参构造方法 有参构造方法。
https://blog.csdn.net/weixin_34779181/article/details/114043567
10.SQL相关
索引失效的情况
1、like的模糊查询以%开头
2、条件中用or,即使其中有条件带索引,也不会使用索引查询
3、查询条件如果是字符串,不加引号会使索引失效
4、not null 不会使用索引, is null 会使用索引
5、使用 <> 或者!=
6、in not in
7、在索引列上使用计算避免索引失效
避免使用*通配符“%”或者“_”作为查询字符串的第一个字符
在设计表时,把索引列设置为NOT NULL
Where子句中避免在索引列上使用计算
索引列上进行函数操作,索引失效
用>= 代替 > 尽量不使用 <> 或者!=
使用EXISTS代替 in 用not EXISTS 代替 not inlike中百分号%的位置
“%” 可用于定义通配符(模式中缺少的字母)
LIKE 'N%' 以 "N" 开始 LIKE '%g' 以 "g" 结尾 LIKE '%lon%' 包含 "lon" NOT LIKE '%lon%' 不包含 "lon" LIKE '_eorge' 第一个字符之后是 "eorge" LIKE 'C_r_er' 以 "C" 开头,然后是一个任意字符,然后是 "r",然后是任意字符,然后是 "er" LIKE '[ALN]%' 以 "A" 或 "L" 或 "N" 开头 LIKE '[!ALN]%' 不以 "A" 或 "L" 或 "N" 开头
外键相关
CREATE TABLE Orders ( Id_O int NOT NULL, OrderNo int NOT NULL, Id_P int, PRIMARY KEY (Id_O), FOREIGN KEY (Id_P) REFERENCES Persons(Id_P) ) DROP FOREIGN KEY fk_PerOrders数据库三大范式
列不可再分
属性完全依赖于主键
不产生传递依赖
三大范式只是一般设计数据库的基本理念,可以建立冗余较小、结构合理的数据库。如果有特殊情况,当然要特殊对待,数据库设计最重要的是看需求跟性能,需求>性能>表结构。所以不能一味的去追求范式建立数据库。实际情况会出现以空间换时间的情况。
左连接和右连接
左连接 where只影向右表,右连接where只影响左表。
inner join:理解为“有效连接”,两张表中都有的数据才会显示
left join:理解为“有左显示”,比如on a.field=b.field,则显示a表中存在的全部数据及a\b中都有的数据,A中有、B没有的数据以null显示
right join:理解为“有右显示”,比如on a.field=b.field,则显示B表中存在的全部数据及a\b中都有的数据,B中有、A没有的数据以null显示
full join:理解为“全连接”,两张表中所有数据都显示,实际就是inner +(left-inner)+(right-inner)
11.Redis常见数据类型
Redis介绍
一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的key-value 键值对存储系统,是跨平台的非关系型数据库。
Redis 通常被称为数据结构服务器,因为值(value)可以是字符串(String)、哈希(Hash)、列表(list)、集合(sets)和有序集合(sorted sets)等类型。
Redis有着更为复杂的数据结构,Redis运行在内存中但是可以持久化到磁盘
Java中使用Redis
安装 Java redis 驱动-> jedis-2.9.0.jar
连接 redis服务
import redis.clients.jedis.Jedis;
public class RedisJava {
public static void main(String[] args) {
//连接本地的 Redis 服务
Jedis jedis = new Jedis("localhost");
// 如果 Redis 服务设置来密码,需要下面这行,没有就不需要
// jedis.auth("123456");
System.out.println("连接成功");
//查看服务是否运行
System.out.println("服务正在运行: "+jedis.ping());
}
}Redis Java String(字符串) /List(列表)/Keys实例
import redis.clients.jedis.Jedis;
public class RedisStringJava {
public static void main(String[] args) {
//连接本地的 Redis 服务
Jedis jedis = new Jedis("localhost");
System.out.println("连接成功");
//设置 redis 字符串数据
jedis.set("runoobkey", "www.runoob.com");
// 获取存储的数据并输出
System.out.println("redis 存储的字符串为: "+ jedis.get("runoobkey"));
//存储数据到列表中
jedis.lpush("site-list", "Runoob");
jedis.lpush("site-list", "Google");
jedis.lpush("site-list", "Taobao");
// 获取存储的数据并输出
List<String> list = jedis.lrange("site-list", 0 ,2);
for(int i=0; i<list.size(); i++) {
System.out.println("列表项为: "+list.get(i));
}
// 获取数据并输出 Keys
Set<String> keys = jedis.keys("*");
Iterator<String> it=keys.iterator() ;
while(it.hasNext()){
String key = it.next();
System.out.println(key);
}
}12.Spring相关
MyBatis介绍
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
SpringBoot介绍
Spring是Java企业版(Java Enterprise Edition,JEE,也称J2EE)的轻量级代替品。无需开发重量级的EnterpriseJavaBean(EJB),Spring为企业级Java开发提供了一种相对简单的方法,通过依赖注入和面向切面编程,用简单的Java对象(Plain Old Java Object,POJO)实现了EJB的功能。
1.使用Spring的IOC容器,将对象之间的依赖关系交给Spring,降低组件之间的耦合性,让我们更专注于应用逻辑
2.可以提供众多服务,事务管理,WS等。
3.AOP的很好支持,方便面向切面编程。
4.对主流的框架提供了很好的集成支持,如Hibernate,Struts2,JPA等
5.Spring DI机制降低了业务对象替换的复杂性。
6.Spring属于低侵入,代码污染极低。
7.Spring的高度可开放性,并不强制依赖于Spring,开发者可以自由选择Spring部分或全部Spring的缺点
- 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的.所有这些配置都代表了开发时的损耗。
- 项目的依赖管理也是一件耗时耗力的事情。
- jsp中要写很多代码、控制器过于灵活,缺少一个公用控制器
- Spring不支持分布式,这也是EJB仍然在用的原因之一。
SpringBoot解决上述Spring的缺点
SpringBoot对上述Spring的缺点进行的改善和优化,基于约定优于配置的思想,可以让开发人员不必在配置与逻辑业务之间进行思维的切换,全身心的投入到逻辑业务的代码编写中,从而大大提高了开发的效率,一定程度上缩短了项目周期。
SpringBoot的特点
为基于Spring的开发提供更快的入门体验
开箱即用,没有代码生成,也无需XML配置。同时也可以修改默认值来满足特定的需求
提供了一些大型项目中常见的非功能性特性,如嵌入式服务器、安全、指标,健康检测、外部配置等
SpringBoot不是对Spring功能上的增强,而是提供了一种快速使用Spring的方式
SpringBoot的核心功能
起步依赖
起步依赖本质上是一个Maven项目对象模型(Project Object Model,POM),定义了对其他库的传递依
赖,这些东西加在一起即支持某项功能。
简单的说,起步依赖就是将具备某种功能的坐标打包到一起,并提供一些默认的功能。
自动配置
Spring Boot的自动配置是一个运行时(更准确地说,是应用程序启动时)的过程,考虑了众多因素,才决定Spring配置应该用哪个,不该用哪个。该过程是Spring自动完成的。
MVC结构的解释
MVC 模式代表 Model-View-Controller(模型-视图-控制器) 模式。这种模式用于应用程序的分层开发。
- Model(模型) - 模型代表一个存取数据的对象或 JAVA POJO。它也可以带有逻辑,在数据变化时更新控制器。
- View(视图) - 视图代表模型包含的数据的可视化。
- Controller(控制器) - 控制器作用于模型和视图上。它控制数据流向模型对象,并在数据变化时更新视图。它使视图与模型分离开。
控制反转和依赖注入
Spring框架的人一定都会听过Spring的**IoC(控制反转) 、DI(依赖注入)**这两个概念
IoC(控制反转):是一种设计思想,在Java开发中,Ioc意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。
●谁控制谁,控制什么:传统Java SE程序设计,我们直接在对象内部通过new进行创建对象,是程序主动去创建依赖对象;而IoC是有专门一个容器来创建这些对象,即由Ioc容器来控制对象的创建;**谁控制谁?当然是IoC容器控制了对象;控制什么?那就是主要控制了外部资源获取(不只是对象包括比如文件等)\。**
●为何是反转,哪些方面反转了:有反转就有正转,传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转;而反转则是由容器来帮忙创建及注入依赖对象;为何是反转?因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转;哪些方面反转了?依赖对象的获取被反转了。
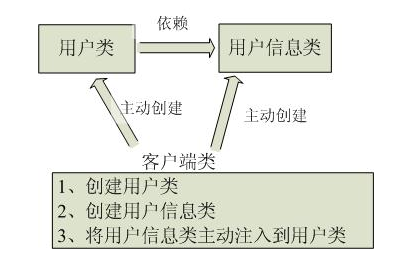
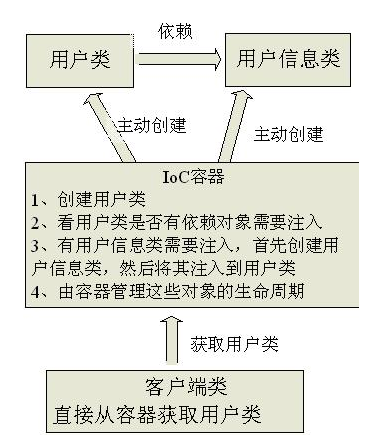
IoC 不是一种技术,只是一种思想,一个重要的面向对象编程的法则,它能指导我们如何设计出松耦合、更优良的程序。传统应用程序都是由我们在类内部主动创建依赖对象,从而导致类与类之间高耦合,难于测试;有了IoC容器后,把创建和查找依赖对象的控制权交给了容器,由容器进行注入组合对象,所以对象与对象之间是 松散耦合,这样也方便测试,利于功能复用,更重要的是使得程序的整个体系结构变得非常灵活。
其实IoC对编程带来的最大改变不是从代码上,而是从思想上,发生了“主从换位”的变化。应用程序原本是老大,要获取什么资源都是主动出击,但是在IoC/DI思想中,应用程序就变成被动的了,被动的等待IoC容器来创建并注入它所需要的资源了。
IoC很好的体现了面向对象设计法则之一—— 好莱坞法则:“别找我们,我们找你”;即由IoC容器帮对象找相应的依赖对象并注入,而不是由对象主动去找。
依赖注入
组件之间依赖关系由容器在运行期决定,形象的说,即由容器动态的将某个依赖关系注入到组件之中。依赖注入的目的并非为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活、可扩展的平台。通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实现。
理解DI的关键是:“谁依赖谁,为什么需要依赖,谁注入谁,注入了什么”,那我们来深入分析一下:
●谁依赖于谁:当然是应用程序依赖于IoC容器;
●为什么需要依赖:应用程序需要IoC容器来提供对象需要的外部资源;
●谁注入谁:很明显是IoC容器注入应用程序某个对象,应用程序依赖的对象;
●注入了什么:就是注入某个对象所需要的外部资源(包括对象、资源、常量数据)。
IoC和DI由什么关系呢?其实它们是同一个概念的不同角度描述,由于控制反转概念比较含糊(可能只是理解为容器控制对象这一个层面,很难让人想到谁来维护对象关系),所以2004年大师级人物Martin Fowler又给出了一个新的名字:“依赖注入”,相对IoC 而言,“依赖注入”明确描述了“被注入对象依赖IoC容器配置依赖对象”。
- 依赖注入的常见方式
构造方法注入
如果只有一个有参数的构造方法并且参数类型与注入的bean的类型匹配,那就会注入到该构造方法中。
Setter注入
在XML中写入,然后在set方法中注入。
基于注解的注入
@Autowired(自动注入)修饰符有三个属性:Constructor,byType,byName。默认按照byType注入。
面经02
作者:煎饼果子这个名字已经被占用了
链接:https://www.nowcoder.com/discuss/621122?channel=-1&source_id=profile_follow_post_nctrack
来源:牛客网
时间 : 20min
plus: 我卡着点进来了 进来的时候面试官已经进来了(QAQ)
自我介绍 说道使用springboot redis之类
springboot启动过程说一下
1.新建module,在主程序类加入断点,启动springboot。
2.首先进入SpringAplication类run方法。
3.run方法新建SpringApplication对象。
4.SpringApplication对象的run方法。
5.run方法首先创建并启动计时监控类。
SpringBootApplication注解由哪几个注解组成
@Configuration: 用于定义一个配置类
@EnableAutoConfiguration :Spring Boot会自动根据你jar包的依赖来自动配置项目。
@ComponentScan: 告诉Spring 哪个packages 的用注解标识的类 会被spring自动扫描并且装入bean容器。
Redis缓存击穿,如何解决(不懂)
缓存击穿,是指对那些会失效的key有高并发的请求,然后在失效的那一瞬间,高并发请求来了,读不到redis的值,全都会把请求打到数据库,导致数据库压力过大
解决方案
1、分布式锁
当发现缓存失效的时候,先使用setnx设置分布式锁,只有获取锁成功的那个线程可以查数据库并回写缓存。优点:能解决问题。
缺点:
1、如果不支持原子操作的话,这个setnx的分布式锁可能会发生死锁。
2、性能一般2、本地锁
同上,只是使用本地锁,解决死锁问题。优点:没有死锁问题
缺点:有多少个机器实例,最多就有多少个“查数据库然后回写redis”的操作
3、软过期
把过期时间写在value中,当读到的时候,发现过期的时候,立马更新过期时间,然后再读数据库、回写。优点:没有死锁问题
缺点:所谓的“立马”更新过期时间,其实也不是原子性的,高并发的时候会有大量的线程认为过期,然后去读数据库。其实也没完全解决大量查数据库的问题,只是减少了查数据库的量。
用的是哪个版本的jdk ? 答1.8 问 :说一下1.8的新特性
- Lambda表达式
- 函数式接口
- *方法引用和构造器调用
- Stream API
- 接口中的默认方法和静态方法
- 新时间日期API
- jvm垃圾收集 参数设置 如何打印线程堆栈信息 性能调优做过么(没做过) 、
垃圾回收算法
1、标记-清除算法(Mark-Sweep)
2、复制算法(Copying)(针对新生代)
3、标记-整理算法(Mark-Compact)(针对老年代)
4、分代收集算法(Generational Collection)
垃圾收集器
1、Serial收集器(用于新生代)
2、ParNew收集器(新生代)
3、Parallel Scavenge收集器(“吞吐量优先”收集器)(新生代)
4、Serial Old收集器(老年代)
5、Parallel Old收集器(老年代)
6、CMS收集器(Concurrent Mark Sweep)
7、G1收集器(Garbage First)
参数总结
UseSerialG
虚拟机运行在client模式下的默认值,打开此开关后,使用Serial+SerialOld的收集器组合进行内存回收。
UserParNewGC
使用ParNew+Serial Old的收集器组合进行内存回收
UserConMarkSweepGC:
使用ParNew+CMS+Serial Old的收集器组合进行内存回收。Serial Old收集器将作为CMC收集器出现Concurrent Mode Fail失败后的后被收集处理器使用
UserParallelGC:
虚拟机运行在client模式下的默认值,使用Parallel Scavenge+Serial Old
(ps MarkSweep)的收集器组合进行内存回收
UserParallelOldGC
使用Parallel+Scavenge+Parallel Old的收集器进行内存回收
SurvivorRatio
新生代中Eden区域与Survivior区域的容量比值,默认为8,代表Eden:Survicor = 8:1
PretenureSizeThreshold
直接晋升老年代对象的大小,设置这个参数后,大于这个参数的对象将直接在老年代分配。
MaxTenuringThreshold
晋升老年代的对象年龄,每个对象在坚持一次Minor GC之后,年龄就增加,当超过这个参数值时就进入老年代
UseAdaptiveSizePolicy
动态调整java堆中各个区域的大小以及进入老年代的年龄
HandlePromotionFailure
是否允许分配担保失败,即老年代的剩余空间不足以应付新生代的整个Eden和survivor区的所有对象都存活的极端情况
ParallelGCThreads
设置并行GC时进行内存回收的线程数
GCTimeRatio
GC时间占总时间的比率,默认值为99,即允许百分之一的GC时间,仅在使用Parallel Scavenge收集器时生效
MaxGCPauseMills
设置GC的最大停顿时间,仅在使用Parallel Scavenge收集器时生效
CMSInitiatingOccupancyFraction
设置CMS收集器在老年代空间被使用多少后触发垃圾收集。默认值为百分之68,仅在使用CMS收集器时生效
UseCMSCompactAtFullCollection
设置CMS收集器在完成垃圾收集后是否进行一次内存碎片整理,仅在使用CMS收集器时生效
CMSFullGCsBeforeCompaction
设置CMS收集器在进行若干次垃圾收集后在启动一次内存碎片整理。仅在使用CMS收集器时生效
创建多线程和关闭线程的方式
继承Thread类创建线程
1】定义Tread类的子类MyThread,并重写run()方法.run()方法的方法体(线程执行体)就是线程要执行的任务。
2】创建MyThread类的实例
3】调用子类实例的start()方法来启动线程
实现Runnable接口创建线程
1】定义Runnable接口的实现类,必须重写run()方法,这个run()方法和Thread中的run()方法一样,是线程的执行体
2】创建Runnable实现类的实例,并用这个实例作为Thread的target来创建Thread对象,这个Thread对象才是真正的线程对象
3】调用start()方法
使用Callable和Future创建线程
1】call方法可以有返回值
2】call()方法可以声明抛出异常
使用线程池创建(使用java.util.concurrent.Executor接口)
继承Thread与实现接口的区别
1】线程只是实现Runnable或实现Callable接口,还可以继承其他类。
2】这种方式下,多个线程可以共享一个target对象,非常适合多线程处理同一份资源的情形。
3】继承Thread类只需要this就能获取当前线程。不需要使用Thread.currentThread()方法
4】继承Thread类的线程类不能再继承其他父类(Java单继承决定)。
5】前三种的线程如果创建关闭频繁会消耗系统资源影响性能,而使用线程池可以不用线程的时候放回线程池,用的时候再从线程池取,项目开发中主要使用线程池的方式创建多个线程。
6】实现接口的创建线程的方式必须实现方法(run() call())。
排序算法 冒泡是稳定排序么 堆排序是稳定排序呢 堆排序空间复杂度
选择排序、快速排序、希尔排序、堆排序不是稳定的排序算法,而冒泡排序、插入排序、归并排序和基数排序是稳定的排序算法
有什么你比较强的领域我没问的么(答 没有QAQ)
没有反问阶段 面试官说面试完毕 等待通知
面经03
作者:找不到工作就去当网管
链接:https://www.nowcoder.com/discuss/611171?channel=-1&source_id=profile_follow_post_nctrack
来源:牛客网
一面大概三十分钟
jvm的内存模型,垃圾回收策略,类加载机制
垃圾回收策略-》垃圾回收算法
类加载机制
Java 的类加载过程可以分为 5 个阶段:载入、验证、准备、解析和初始化。这 5 个阶段一般是顺序发生的,但在动态绑定的情况下,解析阶段发生在初始化阶段之后。
1)Loading(载入)
将字节码从不同的数据源(可能是 class 文件、也可能是 jar 包,甚至网络)转化为二进制字节流加载到内存中,并生成一个代表该类的 java.lang.Class 对象。
2)Verification(验证)
JVM 会在该阶段对二进制字节流进行校验,只有符合 JVM 字节码规范的才能被 JVM 正确执行。该阶段是保证 JVM 安全的重要屏障,下面是一些主要的检查。
3)Preparation(准备)、
JVM 会在该阶段对类变量(也称为静态变量,static 关键字修饰的)分配内存并初始化(对应数据类型的默认初始值,如 0、0L、null、false 等)。
4)Resolution(解析)
该阶段将常量池中的符号引用转化为直接引用。
5)Initialization(初始化)
该阶段是类加载过程的最后一步。在准备阶段,类变量已经被赋过默认初始值,而在初始化阶段,类变量将被赋值为代码期望赋的值。换句话说,初始化阶段是执行类构造器方法的过程。
类加载器
1)启动类加载器(Bootstrap Class-Loader),加载 jre/lib 包下面的 jar 文件,比如说常见的 rt.jar。
2)扩展类加载器(Extension or Ext Class-Loader),加载 jre/lib/ext 包下面的 jar 文件。
3)应用类加载器(Application or App Clas-Loader),根据程序的类路径(classpath)来加载 Java 类。
hashmap1.7和1.8区别,put方法,为什么线程不安全
1.底层结构不一样,1.7是数组+链表,1.8则是数组+链表+红黑树结构;
jdk1.7中当哈希表为空时,会先调用inflateTable()初始化一个数组;而1.8则是直接调用resize()扩容;
插入键值对的put方法的区别,1.8中会将节点插入到链表尾部,而1.7中是采用头插;
redis的基本数据类型,数据淘汰策略,哨兵模式,字典表,redis的底层
springboot的常用注解,为什么可以自动注入bean
前端框架了解哪些
跨域问题,九大内置对象(这个就答上了几个,都忘了)
mysql的索引有哪些,索引失效情况
es的倒排索引,分片和副本是什么
讲一下冒泡排序
如何最快查找出两个list集合中重复的数据
最近看过什么书
沟通表达能力怎么样


